CKA Exam – Troubleshooting 30%
-
-
Evaluate cluster and node logging.
-
-
-
Understand how to monitor applications.
-
-
-
Manage container stdout & stderr logs.
-
-
-
Troubleshoot application failure.
-
-
-
Troubleshoot cluster component failure.
-
Troubleshoot networking.
-
In this page, I will try to demonstrate the questions as per the Linux Foundation pattern.
Please note that these questions may or may not ask in the exam but you will get the fair idea and get the confidence to clear the exam.
1. Evaluate cluster and node logging.
Question: Settings Configuration Environment
Kubectl Config Use-Context K8s
Check how many Nodes are ready (excluding nodes that are set on taint: Noschedule), and write the number to /var/log/k8s00402.txt
Solution:
[root@master1 ~]# Kubectl Config Use-Context K8s
First, check the number of nodes, we have.
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1.example.com Ready control-plane 380d v1.26.9
workernode1.example.com Ready <none> 380d v1.26.9
workernode2.example.com Ready <none> 380d v1.26.9
From the above output, we get to know that there are 3 nodes in our cluster, which are in ready state. Let’s check the taints on all these 3 nodes.
Syntax of command to check the Taint on nodes.
kubectl describe nodes node_name | grep -i taint
[root@master1 ~]# kubectl describe nodes master1.example.com | grep -i taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
[root@master1 ~]# kubectl describe nodes workernode1.example.com | grep -i taint
Taints: <none>
[root@master1 ~]# kubectl describe nodes workernode2.example.com | grep -i taint
Taints: <none>
From the above outputs, we get to know that we have 2 nodes which are not set taint “NoSchedule”. Thus, we can write “2” in the text file.
[root@master1 ~]# echo “2” > /var/log/k8s00402.txt
It’s always a best practice to do the post checks. Hence, cat this file.
[root@master1 ~]# cat /var/log/k8s00402.txt
2
Question completed successfully.
2. Understand how to monitor applications.
One of the best way to enable the application monitoring through Prometheus and Graphana. However, we can also implement the sidecar pod. Prometheus and Graphana are not the part of Kubernetes component. Thus, sidecar question will have high possibility.
Question : Add a busybox sidecar container to the existing Pod customer-red-app. The new sidecar container has to run the following command: /bin/sh -c tail -n+1 -f /var/log/customer-red-app.log
Use a volume mount named logs to make the file /var/log/customer-red-app.log available to the sidecar container.
Don’t modify the existing container.
Don’t modify the path of the log file, both containers must access it at /var/log/customer-red-app.log.
config use : k8s-c1-H
Solution: You need to add one more container in the existing pod.
– name of container is not given. Thus, you can chose whatever you want.
– This new container must write a logs under “/var/log/customer-red-app.log”
First check the pods where it is located.
[root@master1 ~]# kubectl config use-context k8s-c1-H
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
podname 1/1 Running 0 11s
Get all the content in one yaml file.
[root@master1 ~]# kubectl get pods/podname -o yaml > podsname.yaml
Copy this file as a backup. Because we will delete this pod and modify the yaml file.
[root@master1 ~]# cp podsname.yaml podsname.yaml.back
Delete the running pod.
[root@master1 ~]# kubectl delete pods/podname
pod “podname” deleted
Open the “Kubernetes.io” page and Click on “Documentation”. On the left hand side, search “sidecar”. Open the first link and then scroll down and find the below yaml file. Copy these 6 lines and then update as per question.
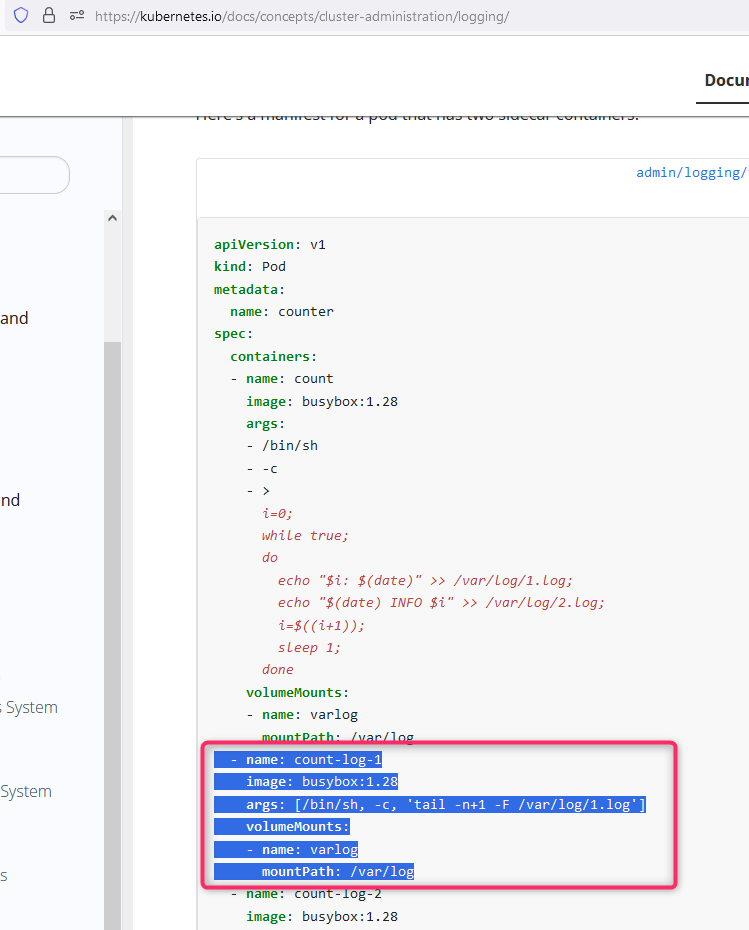
Please take care of indentation. It is very important. Now, open the yaml file that we created earlier and modify it. You need to add 6 lines, see the below blue color lines, inside the container section.
[root@master1 ~]# vi podsname.yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
cni.projectcalico.org/containerID: 56bdc95fc52ba447c6fd2d51643b5ed883864b8405737e615e2a144fd33d2bba
cni.projectcalico.org/podIP: 172.16.14.104/32
cni.projectcalico.org/podIPs: 172.16.14.104/32
kubectl.kubernetes.io/last-applied-configuration: |
{“apiVersion”:”v1″,”kind”:”Pod”,”metadata”:{“annotations”:{},”name”:”podname”,”namespace”:”default”},”spec”:{“containers”:[{“args”:[“/bin/sh”,”-c”,”i=0; while true; don echo “$(date) INFO $i” u003eu003e /var/log/customer-red-app.log;n i=$((i+1));n sleep 1;ndonen”],”image”:”busybox”,”name”:”count”,”volumeMounts”:[{“mountPath”:”/var/log”,”name”:”logs”}]}],”volumes”:[{“emptyDir”:{},”name”:”logs”}]}}
creationTimestamp: “2023-12-23T11:43:54Z”
name: podname
namespace: default
resourceVersion: “852677”
uid: a8fd3950-df74-444f-ab51-6a023c797f35
spec:
containers:
– name: sidecarbusybox
image: busybox
args: [/bin/sh, -c, ‘tail -n+1 -f /var/log/customer-red-app.log’]
volumeMounts:
– mountPath: /var/log
name: logs
– args:
– /bin/sh
– -c
– |
i=0; while true; do
echo “$(date) INFO $i” >> /var/log/customer-red-app.log;
i=$((i+1));
sleep 1;
done
image: busybox
imagePullPolicy: Always
name: count
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
– mountPath: /var/log
name: logs
– mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-sfk7w
readOnly: true
dnsPolicy: ClusterFirst
[root@master1 ~]# kubectl apply -f podsname.yaml
pod/podname created
[root@master1 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
podname 2/2 Running 1 (9s ago) 12s
One can observe that now, we have 2 containers are running.
How to verify it ?
Syntax of command : kubectl logs pods/POD_NAME -c Container_NAME
[root@master1 ~]# kubectl logs pods/podname -c sidecarbusybox | head
Sat Dec 23 11:57:02 UTC 2023 INFO 0
Sat Dec 23 11:57:03 UTC 2023 INFO 1
Sat Dec 23 11:57:04 UTC 2023 INFO 2
Sat Dec 23 11:57:05 UTC 2023 INFO 3
Sat Dec 23 11:57:06 UTC 2023 INFO 4
Sat Dec 23 11:57:07 UTC 2023 INFO 5
Sat Dec 23 11:57:08 UTC 2023 INFO 6
Sat Dec 23 11:57:09 UTC 2023 INFO 7
Sat Dec 23 11:57:10 UTC 2023 INFO 8
Sat Dec 23 11:57:11 UTC 2023 INFO 9
3. Manage container stdout & stderr logs.
Question 3 : Monitor the logs of pod tata-bar and extract log lines corresponding to error website is down- unable to access it. Write them to /opt/KUTR00101/tata-bar
Solution: There is a pod running and you need to extract the string and save it on one file.
How to see the logs of pods?
[root@master1 ~]# kubectl logs tata-bar
website is down- unable to access it
website is down- unable to access it
website is down- unable to access it
website is down- unable to access it
website is down- unable to access it
website is down- unable to access it
[root@master1 ~]#
If we want to send the logs to another file then use “>” append symbol.
[root@master1 ~]# kubectl logs tata-bar > /opt/KUTR00101/tata-bar If you want to practice at home, and wondering how to create this pod. Then here is the solution.
Go to below URL or edit the yaml file like below:
https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/
Due to page formatting, indentation of below yaml file will be changed when you paste in your terminal. Thus use below copy button.
apiVersion: v1
kind: Pod
metadata:
name: tata-bar
labels:
purpose: demonstrate-command
spec:
containers:
- name: command-demo-container
image: debian
command: ["/bin/sh"]
args: ["-c", "while true; do echo website is down- unable to access it; sleep 10; done"]
restartPolicy: OnFailure
kubectl create -f tata-bar.yaml
Next question on this would be…..
From the pod label name=app-nginx, find pods running high CPU workloads and write the name of the pod consuming most CPU to the file /var/log/KUT00401.txt (which already exists).
Use context: kubectl config use-context k8s-c1-H
Solution:
[root@master1 ~]# kubectl config use-context k8s-c1-H
[root@master1 ~]# kubectl get pods -l name=app-nginx
NAME READY STATUS RESTARTS AGE
cpu-pod1 1/1 Running 0 68s
cpu-pod2 1/1 Running 0 20s
max-pod1 1/1 Running 0 7s
Now, use the “top” sub command to check the high CPU utilization pod name.
[root@master1 ~]# kubectl top pods -l name=app-nginx
NAME CPU(cores) MEMORY(bytes)
cpu-pod1 100m 2Mi
cpu-pod2 30m 2Mi
max-pod1 10m 2Mi
Put the higest CPU ulitzation pod name in the give file.
[root@master1 ~]# echo “cpu-pod1” > /var/log/KUT00401.txt
[root@master1 ~]# cat /var/log/KUT00401.txt
cpu-pod1
[root@master1 ~]#
4. Troubleshoot application failure.
Question 2: Set the node named workernode1.example.com as unavailable and reschedule all the pods running on it.
Use context:kubectl config use-context ek8s
Solution: In this question, it is asked indirectly to put this node on maintenance mode.
Change the context
kubectl config use-context ek8s
Check the context
kubectl config current-context
Observe the running pods on all nodes. Just check the workernode1, how many pods are working.
kubectl get pods -o wide
You can also check all the node names.
kubectl get nodes
Put the node on maintenance mode, cordon is the sub command and the followed by nodename.
kubectl cordon workernode1.example.com
Move all the pods to another nodes.
kubectl drain workernode1.example.com --ignore-daemonsets --force
Check all pods moved from workernode1 to another node. In exam node name must be changed.
kubectl get pods -o wide5. Troubleshoot cluster component failure.
Use context: kubectl config use-context k8s-c2-AC
Kubernetes worker node named workernode2.example.com is in a NotReady state. Investigate the root cause and resolve it. Ensure that any changes made are permanently effective.
– You can use the following command to connect to the fault node:
ssh worker2.example.com
– You can use the following command to get higher permissions on this node:
sudo -i
Solution:
Use the correct context.
[root@master1 ~]# Kubectl Config Use-Context Ek8s
Check the node status.
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1.example.com Ready control-plane 381d v1.26.9
workernode1.example.com Ready <none> 380d v1.26.9
workernode2.example.com NotReady <none> 381d v1.26.9
[root@master1 ~]#
Loging to workernode2 and use the command which is given in the question.
[root@master1 ~]# ssh workernode2
Raise the privileges by executing the command “sudo -i”. This command will also be provided in the question.
[arana@workernode2 ~]$ sudo -i
[root@workernode2 ~]#
KUBELET is a agent and it is responsible to connect with master node. Thus, check the service of kubelet.
[root@workernode2 ~]# systemctl status kubelet
○ kubelet.service – kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead) since Sat 2023-12-23 22:24:36 IST; 2min 56s ago
Duration: 5h 49min 33.339s
Docs: https://kubernetes.io/docs/
Process: 770 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=0/SUCCESS)
Main PID: 770 (code=exited, status=0/SUCCESS)
CPU: 2min 15.540s
Dec 23 22:23:07 workernode2.example.com kubelet[770]: I1223 22:23:07.283124 770 log.go:194] http: TLS handshake error from 192.168.1.32:60088: remote error: tls: bad certificate
Dec 23 22:23:22 workernode2.example.com kubelet[770]: I1223 22:23:22.268391 770 log.go:194] http: TLS handshake error from 192.168.1.32:4435: remote error: tls: bad certificate
Dec 23 22:23:37 workernode2.example.com kubelet[770]: I1223 22:23:37.280033 770 log.go:194] http: TLS handshake error from 192.168.1.32:61478: remote error: tls: bad certificate
Dec 23 22:23:52 workernode2.example.com kubelet[770]: I1223 22:23:52.271086 770 log.go:194] http: TLS handshake error from 192.168.1.32:8049: remote error: tls: bad certificate
Dec 23 22:24:07 workernode2.example.com kubelet[770]: I1223 22:24:07.285566 770 log.go:194] http: TLS handshake error from 192.168.1.32:53329: remote error: tls: bad certificate
Dec 23 22:24:22 workernode2.example.com kubelet[770]: I1223 22:24:22.264235 770 log.go:194] http: TLS handshake error from 192.168.1.32:51315: remote error: tls: bad certificate
Dec 23 22:24:36 workernode2.example.com systemd[1]: Stopping kubelet: The Kubernetes Node Agent…
Dec 23 22:24:36 workernode2.example.com systemd[1]: kubelet.service: Deactivated successfully.
Dec 23 22:24:36 workernode2.example.com systemd[1]: Stopped kubelet: The Kubernetes Node Agent.
Dec 23 22:24:37 workernode2.example.com systemd[1]: kubelet.service: Consumed 2min 15.540s CPU time.
From the above command output, it is clear that kubelet service is not running. Next, to start the service.
[root@workernode2 ~]# systemctl start kubelet
Check the kubelet service
[root@workernode2 ~]# systemctl status kubelet
● kubelet.service – kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Sat 2023-12-23 22:31:28 IST; 4s ago
Docs: https://kubernetes.io/docs/
Main PID: 168384 (kubelet)
Tasks: 10 (limit: 13824)
Memory: 34.8M
CPU: 250ms
CGroup: /system.slice/kubelet.service
└─168384 /usr/bin/kubelet –bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf –kubeconfig=/etc/kubernetes/kubelet.conf –config=/var/lib/kubelet/config.yaml –container-runt>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.096918 168384 kubelet_node_status.go:73] “Successfully registered node” node=”workernode2.example.com”
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.147476 168384 kubelet_node_status.go:493] “Fast updating node status as it just became ready”
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.215099 168384 topology_manager.go:210] “Topology Admit Handler” podUID=c6121c46-99de-4b99-b7ce-97ceb0add518 podNamespace=”ku>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: E1223 22:31:31.215153 168384 cpu_manager.go:395] “RemoveStaleState: removing container” podUID=”a1d210b0-1e23-46dc-bbcf-a497d8440a48″ conta>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.215178 168384 memory_manager.go:346] “RemoveStaleState removing state” podUID=”a1d210b0-1e23-46dc-bbcf-a497d8440a48″ contain>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.345454 168384 reconciler_common.go:253] “operationExecutor.VerifyControllerAttachedVolume started for volume “tmp-dir” (Un>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: I1223 22:31:31.345550 168384 reconciler_common.go:253] “operationExecutor.VerifyControllerAttachedVolume started for volume “kube-api-acce>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: E1223 22:31:31.451919 168384 projected.go:292] Couldn’t get configMap default/kube-root-ca.crt: object “default”/”kube-root-ca.crt” not reg>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: E1223 22:31:31.451952 168384 projected.go:198] Error preparing data for projected volume kube-api-access-sfk7w for pod default/podname: obj>
Dec 23 22:31:31 workernode2.example.com kubelet[168384]: E1223 22:31:31.452004 168384 nestedpendingoperations.go:348] Operation for “{volumeName:kubernetes.io/projected/0b06b8d2-2078-4929-8eb9-b2e>
In the question, it is asked us to make the changes permanent. Thus, use the enable sub command to make the changes permanent.
[root@workernode2 ~]# systemctl enable kubelet
Exist from the workernode2 and check the the status of our node.
[root@workernode2 ~]# exit
logout
[arana@workernode2 ~]$ exit
logout
Connection to workernode2 closed.
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1.example.com Ready control-plane 381d v1.26.9
workernode1.example.com Ready <none> 381d v1.26.9
workernode2.example.com Ready <none> 381d v1.26.9
[root@master1 ~]#
6. Troubleshoot networking.
Qestion 4: Reconfigure the existing deployment front-end-var and add a port specification named http exposing port 80/tcp of the existing container nginx.
Create a new service named “front-end-var-svc-var” exposing the container port http.
Configure the new service to also expose individual Pods via a NodePort on the nodes on which they are scheduled.
Solution:
What we have, deployment name “front-end-var”, which is already running. What is asked us, expose this deployment to new service “front-end-app-svc” on NodePort service on port 80.
kubectl expose deployment front-end-var --name=front-end-var-svc-var --port=80 --target-port=80 --protocol=TCP --type=NodePort[root@master1 ~]# kubectl get service front-end-var-svc-var
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
front-end-var-svc-var NodePort 10.101.245.122 <none> 80:30521/TCP 12s
[root@master1 ~]# curl http://10.101.245.122:80 | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 615 100 615 0 0 600k 0 --:--:-- --:--:-- --:--:-- 600k
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
[root@master1 ~]#